Overview
We implemented a ROS2 Package that extracts synchronized stereo or monocular raw image frames from an Intel RealSense Camera. Upon initialization, the node configures itself based on runtime parameters including camera mode (stereo/monocular), feature extraction method (ORB/SIFT), and optimization frequency. For stereo operation, it establishes synchronized subscribers for both infrared cameras and their calibration data, while monocular mode uses the color camera stream.
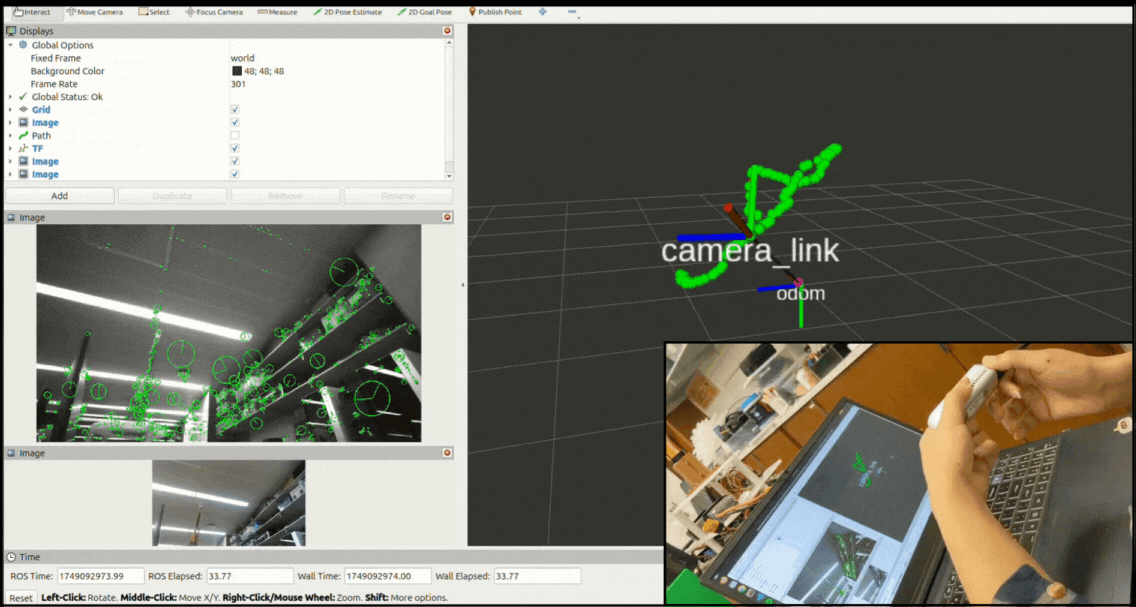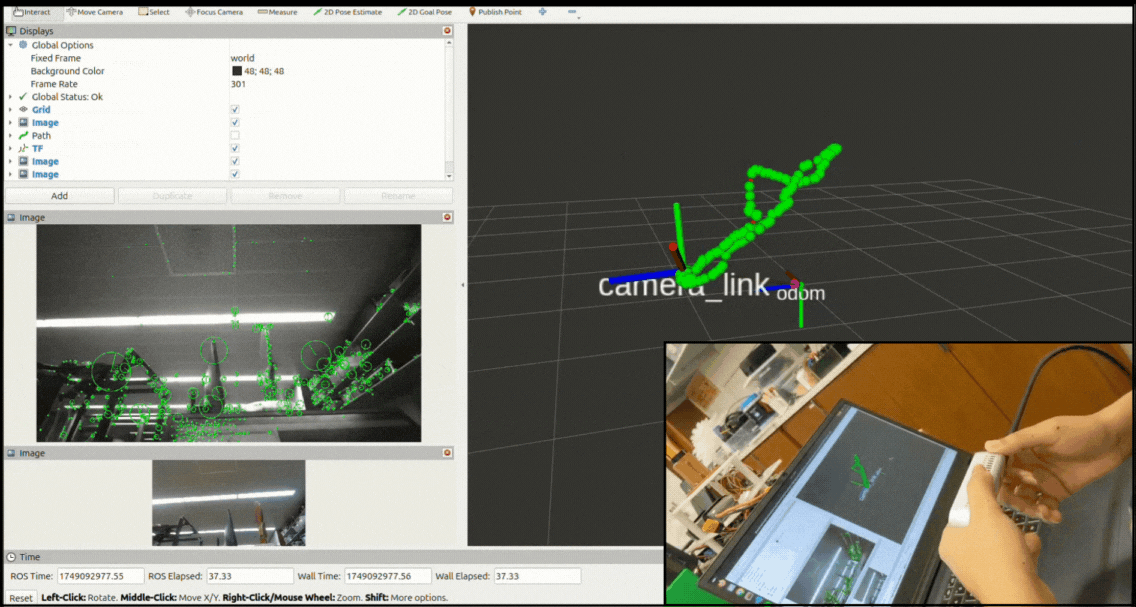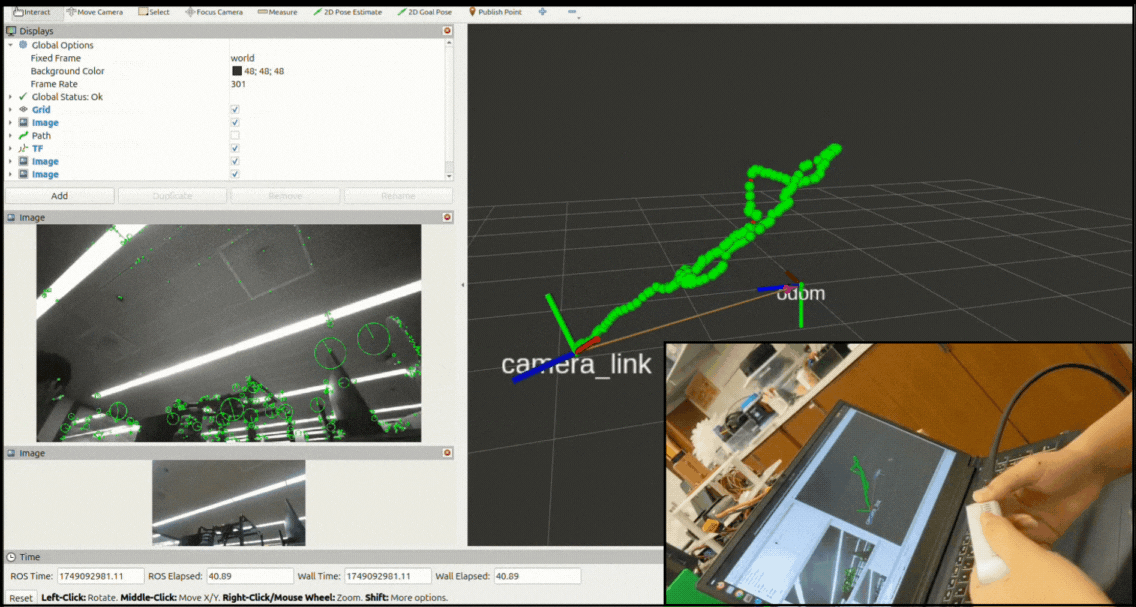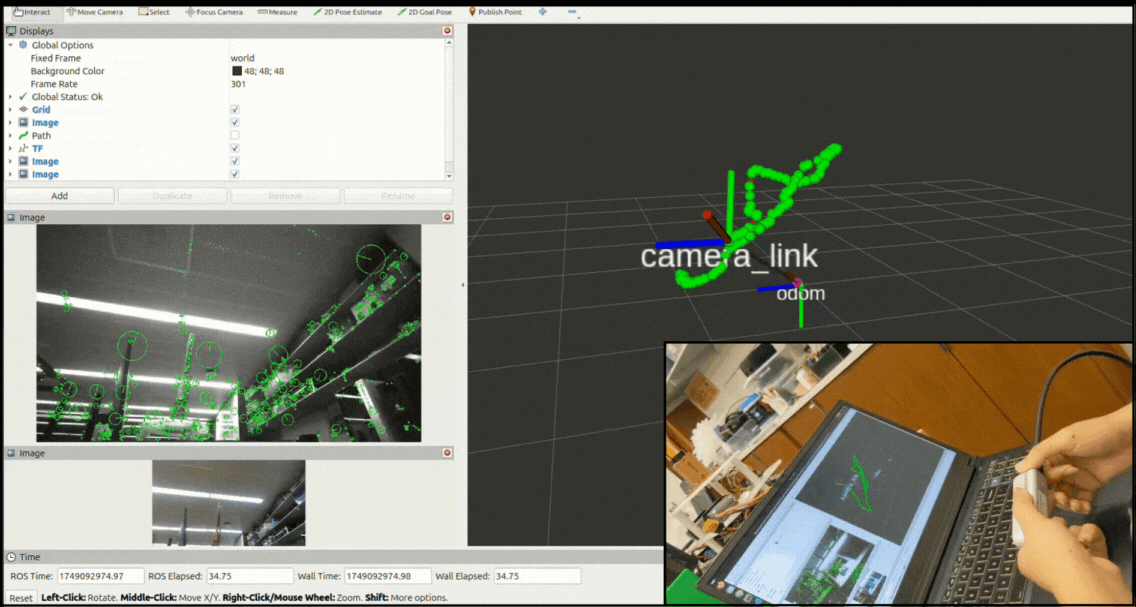
System Architechture
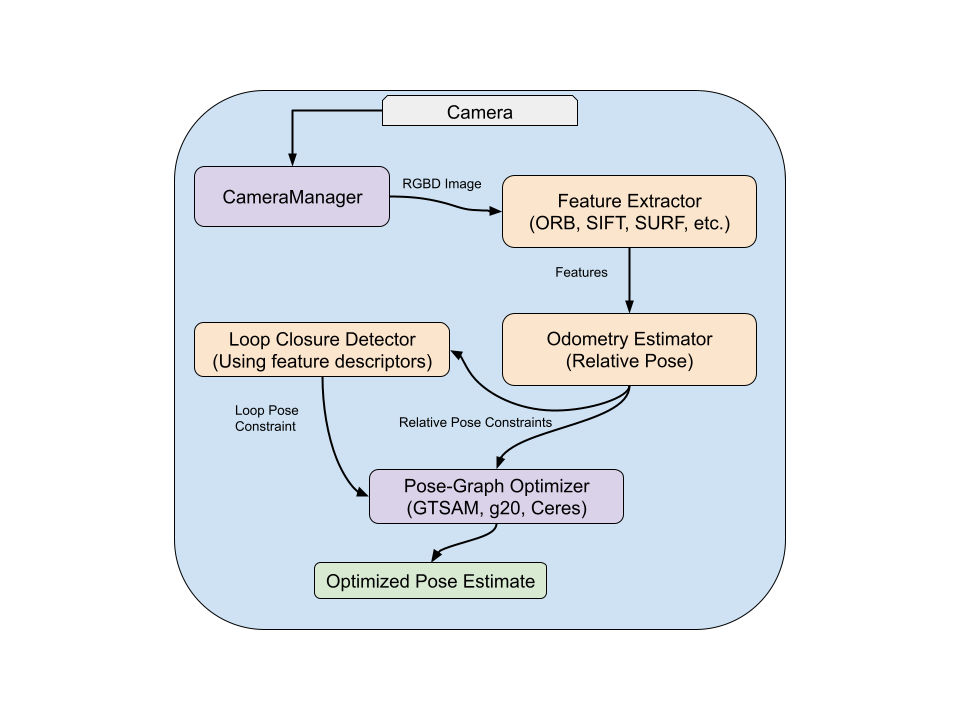
The overall modular design allows easy swapping of components - for instance, changing from g2o to GTSAM for optimization or integrating additional sensors like IMUs through the ROS 2 interface. The system subscribes to stereo images and processes them only when left + right images and their camera info are synchronized. The synchronizedStereoCallback is triggered once per stereo pair, effectively driving the frontend pipeline (ORB features, tracking) at 15–30 Hz depending on frame sync and load. Backend pose graph optimization runs asynchronously at a lower frequency (~10 Hz) to maintain frontend responsiveness. This architecture ensures real-time operation while decoupling compute-heavy optimization from perception.
Feature Extraction
This forms the core frontend processing, where each incoming frame is analyzed using the selected algorithm. The implementation provides interchangeable feature detectors through OpenCV’s features2D module, with extracted features including both keypoint locations and their descriptors. These features are then published as visualized overlays on the original images for debugging purposes. For stereo configurations, matching features between left and right images enables 3D point triangulation using the known baseline distance.
Mono Vs Stereo
Initially we implemented monocular feature extraction and pose estimation using the rect topic of realsense. Then we switched to using both the right and left raw image frames, intrinsic and extrinsic camera data, and geometry (baseline). Then we used the PnP RANSAC to triangulate the feature keypoints and descriptors.
ORB Vs SIFT
ORB seemed faster but thus better for long runs, like if the track was covering a large distance. But SIFT detects the feature better, and better for our use case.

ORB

SIFT
Visual odometry estimation
This step occurs through feature matching between consecutive frames using FLANN-based matchers. The system computes relative camera motion by first finding the essential matrix with RANSAC outlier rejection, then decomposing it into rotation and translation components. In stereo mode, this is enhanced with direct 3D point triangulation from matched features across the stereo pair. Each estimated pose forms a node in the pose graph, with odometry constraints creating edges between consecutive nodes.
Backend optimization system
We utilized the g2o’s sparse optimizer with Levenberg-Marquardt solving. Nodes represent SE(3) camera poses while edges encode relative transformations between them. The first node is fixed as a reference frame, with subsequent nodes added as new frames are processed. Loop closure detection, though not fully implemented in the current version, is designed to add additional constraints when revisited locations are identified through feature matching against previous keyframes. The graph is built real time and its optimisation loop runs asynchronously at a lower frequency (~10 Hz) to maintain the frontend responsiveness.
Visualization
The system maintains three main outputs:
- A continuously updating camera trajectory published as a ROS Path message,
- Transform frames broadcast through tf2 representing the current camera pose estimate, and
- A pose-graph visualization showing nodes and edges as interactive markers in RViz.
The implementation handles thread safety through mutex locks when accessing shared resources like the current pose estimate and optimization graph.
Hardware


Custom Vs ZED2i VIO
Our visual-pose system matches ZED2i SDK’s relative positional accuracy but lacks its IMU fusion for robust tracking during motion. While both run at 30Hz, our CPU-based OpenCV/g2o pipeline offers research flexibility versus ZED2i’s optimized hardware processing. ZED2i provides out-of-the-box Kalman filtering and confidence-based weighting and ROS2 wrappers making it easy to integrate to hardware devices. Thus, overall our system is good for customization and understanding the concepts and, ZED2i for plug-and-play performance.
Extended Application
This visual pose estimation system has been extended and utilized in another project. You can find details 🚀 here.
Limitations
- Our pose-estimation pipeline has a teleportation issue where the odom jumps to another location but on both the locations the relative motion of poses remains correct.
- The inherent noise of using only visual features and not considering the physics of the environment in our pipeline.
Future Work
- We plan to incorporate wheel encoder data into a tightly-coupled sensor fusion filter. Encoder ticks will be converted to incremental poses through differential-drive kinematics and aligned with the camera–IMU extrinsic calibration. And implement Extended Kalman Filter (EKF) or factor-graph approach to fuse VIO pose deltas and encoder-derived odometry constraints. These additionalodometry edges in the pose graph will anchor the visual estimates, yielding more robust trajectory estimates.
- Incorporate confidence estimation into the pose graph by assigning uncertainty metrics to each pose and constraint edge. These metrics will be erived from sensor noise models. This allows the system to reject physically implausible trajectory segments, weigh constraints based on dynamics-consistency, and this should theoretically improve trajectory smoothness and the teleportation issue.
- Test ML Based techques like SuperPoint Network and use this as a benchmark to compare.
- Deploy on edge devices like the NVIDIA Jetson to assess performance in resource-constrained environment.